概述
在实际使用中,经常会遇见一些特殊的需求,比如:
- 部分需要显示的冷僻字(比如出现在公司名、地名、人名),GB2312中不含有这个字,但是又不想为了这一个字使用庞大的GBK字库(太占内存)
- 部分特殊字符,比如“㎥”,常规GB2312字库无法使用
- 常用显示的wifi信号强度,单色,如果能使用空白汉字区域来显示,也就是自定义点阵,就会很方便
- 其他一些国家的文字,比如少量韩文,我们通过此方法将一些空白内码强指定成韩文已显示
解决方案
考虑到这是一个高级技巧,因此不再设计应用界面,我们采用手工维护JSON文件的方式完成配置,方法如下:
在c:/shmictrl/work/ 目录下,创建一个customerfont.json 文件,内容如下:(注意:JSON文件必须使用UTF8编码,样例文件可以通过: http://shmictrl.com/download/customerfont.json 下载得到)
本方法有两种模式,一种模式是替换,一种模式是自定义点阵;详细见最下面备注。
{
"6":{
"あ":"㎥",
"ABA1":"㎥",
"ABA2":"0xF0,0x00,0x00,0x00,0x3F,0xFC,0x20,0x04,0x2F,0xF4,0x20,0x04,0x20,0x04,0x20,0x04,0x20,0x84,0x20,0x84,0x20,0x84,0x20,0x84,0x20,0x04,0x3F,0xFC,0x00,0x00,0x01,0xC0",
}
}可以看到,这是一个JSON的标准格式,JSON以{ }开始,其中的“6”表示我们针对6号字体进行设置:
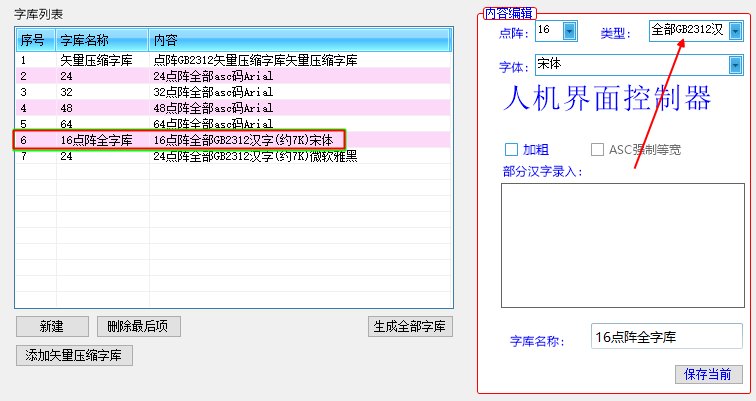
在这个样例中,我们可以看到6号字体是GB2312的16点阵字体,本自定义配置只有在选择“全部GB2312汉字”这个用户自定义字模配置文件才能生效!!
在实际使用中,我们可以把一些不常用的汉字,比如日文,替换成需要使用的特殊汉字,由于JSON文件是UTF8的,因此一些UTF8中才能显示的字符,也可以显示出来,比如韩文。
"あ":"㎥", //这个意思是,把"あ"替换成"㎥",生成字库点阵后,凡是送的内码"あ"都会显示成"㎥"
"ABA1":"㎥",//这个意思是汉字内码是0xABA1的这个汉字,点阵数据被替换成"㎥"
//附:0xABA1的汉字"";0xABA2的汉字"";0xABA3的汉字""
//ABA1这种方式主要用于那些显示起来完全空白的汉字,这种汉字无法从肉眼感测到具体是哪个汉字,因此使用16进制内码更好一些还有一种方式就是点阵了,比如我们使用 一些工具,来设计一个16X16的点阵:
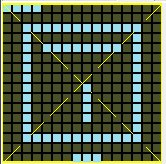
于是,工具生成了一组16进制的点阵数据:
"ABA2":"0xF0,0x00,0x00,0x00,0x3F,0xFC,0x20,0x04,0x2F,0xF4,0x20,0x04,0x20,0x04,0x20,0x04,0x20,0x84,0x20,0x84,0x20,0x84,0x20,0x84,0x20,0x04,0x3F,0xFC,0x00,0x00,0x01,0xC0",我们把它赋值给ABA2就可以,于是:

图中 TEXT的字符串为:"开始あ其中:开后面跟的是ABA1的汉字,然后是ABA2的汉字,最后是"始あ"
【备注:两种模式】
1、汉字替换只支持“GB2312全字库”,不支持GBK和小字库
"あ":"㎥",
"ABA1":"㎥"这两种模式只支持“GB2312全字库”,不支持GBK和小字库
2、汉字自定义点阵模式支持“GB2312全字库”和小字库,不支持GBK汉字库
"ABA2":"0xF0,0x00,0x00,0x00,0x3F,0xFC,0x20,0x04,0x2F,0xF4,0x20,0x04,0x20,0x04,0x20,0x04,0x20,0x84,0x20,0x84,0x20,0x84,0x20,0x84,0x20,0x04,0x3F,0xFC,0x00,0x00,0x01,0xC0",这种就是汉字点阵模式,不过汉字点阵也可以使用界面工具来维护,详细参见:自定义汉字点阵编辑